Just Enough R for IDM
The Pipe Operator
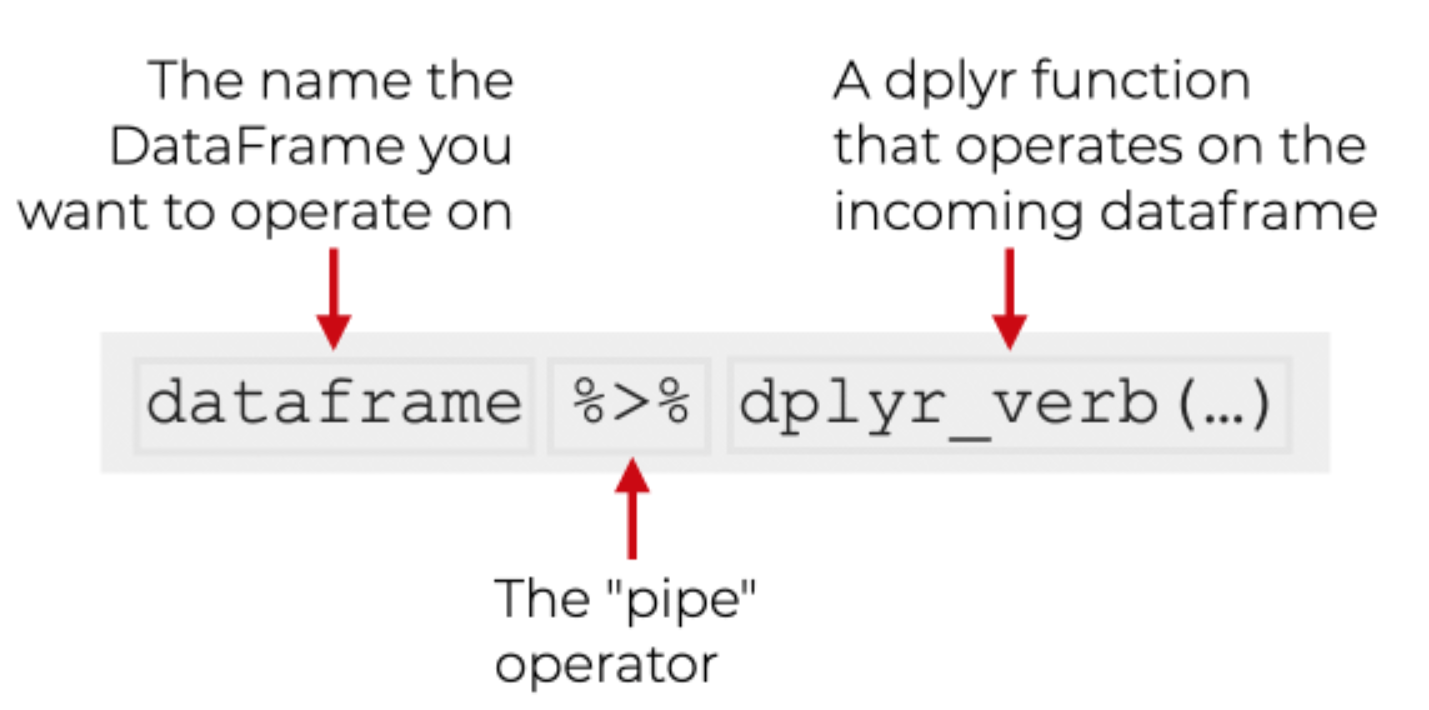
Read |> out loud as “and then…”. x |> f() is the same as f(x). x |> f() |> g() is g(f(x)).
filter() function - Keeps the Rows
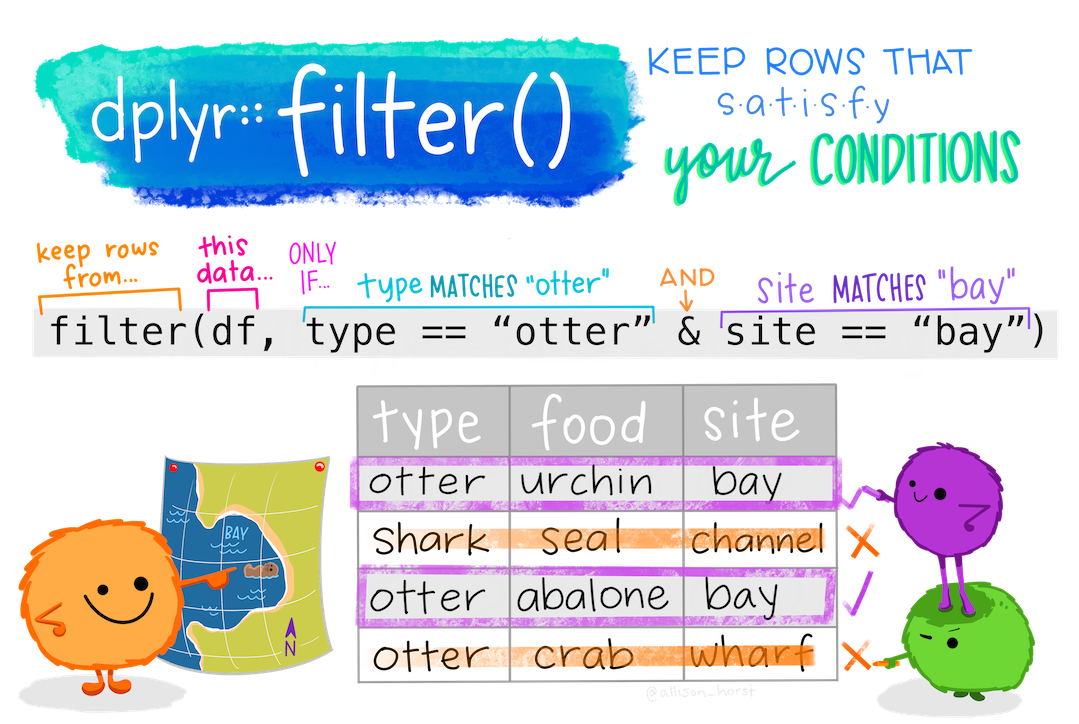
Logical Operators in filter()

mutate() function: Makes New Columns

The Plot

The Line List → Plot Pipeline
library(tidyverse)
library(outbreaks)
library(lubridate)
ll <- outbreaks::ebola_sim_clean$linelist |> as_tibble()
ll |>
filter(!is.na(date_of_onset)) |>
mutate(month = floor_date(date_of_onset, "month")) |>
group_by(month, gender) |>
summarise(cases = n(), .groups = "drop") |>
ggplot(aes(month, cases, fill = gender)) +
geom_col(position = "dodge") +
labs(x = "Month", y = "Cases",
title = "Ebola simulated outbreak — monthly cases by gender")
Five verbs. One pipeline. Read it top-to-bottom as English.
The “Epi Way” — Two Lines, Same Plot

Same idea — three lines instead of seven. Epi packages give you tidy shortcuts for common patterns. Bridge to Rt in Foundations.
COVID-19 India — Daily Cases
library(tidyverse); library(EpiEstim); library(here)
covid_india <- read_csv(here("data", "covid_india_daily.csv"),
show_col_types = FALSE) |>
transmute(dates = as.Date(date),
I = as.integer(daily_confirmed)) |>
arrange(dates) |>
filter(!is.na(I))
covid_india |>
ggplot(aes(dates, I)) +
geom_col(fill = "steelblue") +
scale_y_continuous(labels = scales::comma) +
labs(x = NULL, y = "Daily confirmed cases",
title = "COVID-19 India — JHU CSSE, 2020-01 to 2023-03")